Raft 논문을 선택한 이유
작년에 참여한 카프카 소모임에서 zookeeper 대신 kraft 가 등장할 것 이란 얘길 들은적이 있다.
카프카도 kraft도 모르던 시절이라 어떻게 주키퍼를 대체한다는 건지, 막연한 궁금증만 가졌다.
그러다 최근 분산 시스템 스터디에서 raft 를 학습하며 이것이 곧 kraft 의 근간이 된다는 점을 알게 됐다.
뿐만 아니라 쿠버네티스 클러스터 구축에 필요한 etcd 도 raft 합의 알고리즘에 기조한다는 점이 흥미롭게 다가와 이를 제대로 배워보고자 논문을 읽게 됐다.
Raft 란 무엇인가?
그래서 Raft 란 무엇인가? Raft 는 분산 시스템에서 복제된 로그를 관리하기 위한 합의 알고리즘이다.
분산시스템에서 로그는 개별 노드에 복제되어 영속화된다. 이 때 로그를 안전하고 일관성 있는 방향으로 복제하기 위한 절차를 합의 알고리즘 이라 부른다.
즉 Raft 는 분산 시스템에서 리더 선출과 로그 복제를 통해 여러 노드 간의 데이터를 일관되게 유지하는 합의 알고리즘 이다.

Raft 가 등장할 수 밖에 없던 배경
논문의 제목에서 알 수 있듯이 Raft 는 이해할 수 있는(Understandable) 측면에 포커스를 둔다.
이전의 합의 알고리즘은 어땠길래 Understandable 이란 워딩까지 사용하며 Raft 를 소개하는 걸까?
Raft 이전의 널리 알려진 합의 알고리즘은 Lesile Lamport (83) 가 고안한 Paxos Protocol 으로,
논문에선 당시 스탠포드 대학의 학생들도 이를 이해하는데 1년이 넘는 시간이 걸렸다고 소개한다.
Raft 는 "이해 가능한" 이란 측면에서 중점을 둔 이론으로
Paxos 만큼 효율적인 알고리즘이지만, Paxos 보다 이해하기 쉬운 알고리즘이기도 한 셈이다.
복제 상태 머신 이란?
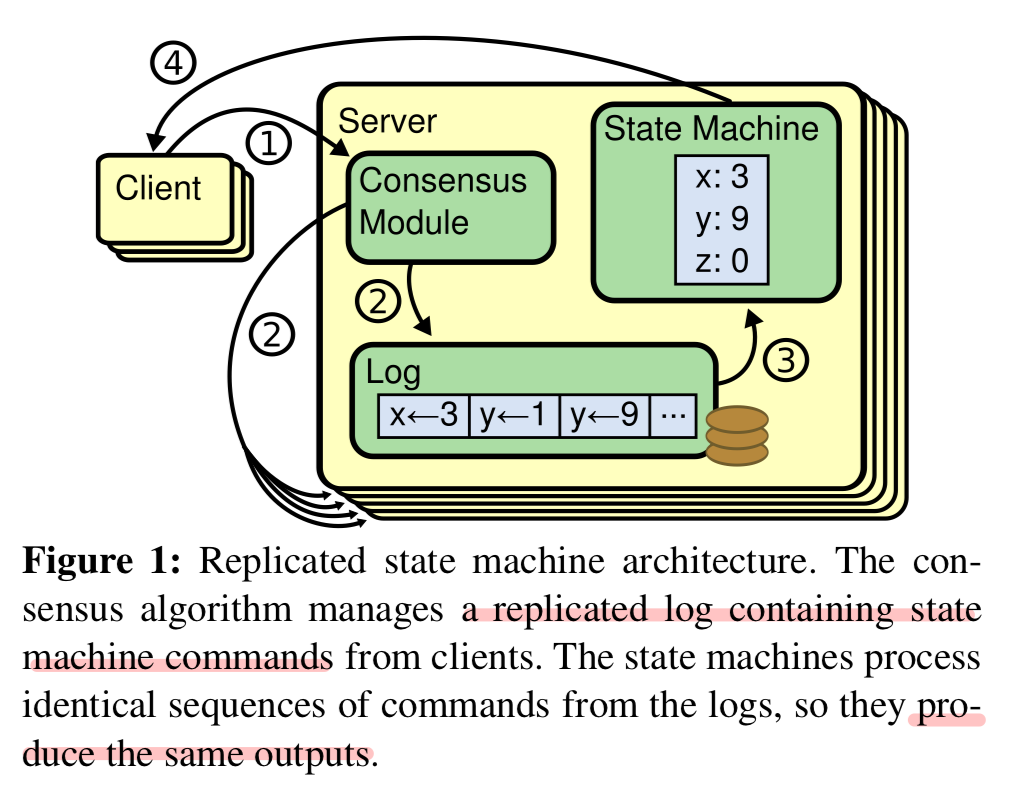
합의 알고리즘은 복제 상태 머신 (Replicated State Machine) 개념에서 출발한다.
복제 상태 머신이란 무엇일까? 복제 상태 머신은 분산 시스템의 여러 노드가 동일한 상태를 유지하기 위해 사용되는 개념으로,
분산된 노드들이 동일한 명령을 순서대로 실행하여 노드 간 일관된 상태를 보장한다.
여기서 머신이란 클러스터의 노드 즉 서버를 의미하며 같은 명령을 순서대로 실행한다는 것은 특정 노드의 상태를 변경(x <- 5)하는 명령이 입력되면,
나머지 노드에서도 동일한 명령이 실행됨을 의미힌다.
이렇게 노드 간의 일관된 상태가 보장되면 클러스터의 가용성(availability)이 높아져 분산 시스템을 더 안전하게 운영할 수 있다.
정리하면, 복제 상태 머신은 합의 알고리즘을 바탕으로 분산 시스템의 다양한 내결함성 문제를 해결하는 핵심 요소라 할 수 있다.
복제 상태 머신은 어떻게 모든 노드를 일관된 상태로 유지할 수 있을까?
이를 가능케 하는 것이 바로 복제 로그로, 클러스터에 연결된 모든 노드에 사용자의 명령어를 동일한 순서로 저장한다.
만약 리더 노드에 (a <- 1, b <- 2, c <- 1) 순서로 명령이 입력되면, 클러스터의 모든 노드에서 예외 없이 동일한 순서로 해당 명령을 실행한다.
일관된 로그를 복제함으로써 각 노드는 로그의 명령(command)을 순차적으로 실행하여 동일한 상태를 만들 수 있다.
상태 머신은 결정론적(deterministic) 이기 때문에 같은 상태를 계산하면 동일한 순서로 결과를 반환한다.
📌 결정론적 (Deterministic) : 결정론적 알고리즘이란 특정 입력(input) 에 대해 특정 결과(output)를 반환하는 의미로, 여러 복제된 상태 머신들이 동일한 복제 로그를 토대로 명령을 실행하면, 분산 노드들은 결국 같은 결과를 반환할 수 있다.
복제 상태 머신의 특징과 속성
복제 상태 머신이 노드 간 일관성을 유지하기 위해 지켜야할 특징은 무엇이 있을까.
-
우선
안정성을 유지하려면 네트워크 지연/패킷 손실/중복 전송 같은 Non-Byzantine 오류에서도 결함 없이 작동해야 한다. -
충돌 회피로 각 노드가 서로 다른 결정이나 결과를 만들지 않도록 하며, 장애 상황에서도 동기화된 상태를 유지해야 한다. -
일관된 메시지 전달이 가능해야 하며, 네트워크에서 메시지가 손실되거나 지연될 수 있지만 임의로 변조되지 않아야 한다. -
가용성을 보장하기 위해 클러스터 서버 중 과반수 이상이 정상 작동하고 서로 통신이 가능하면 일부 서버에서 장애가 발생해도 시스템을 유지할 수 있어야 한다. 예를 들어, 5개의 서버 중 최대 2대의 서버가 중단되어도 클러스터는 기능을 유지하며 과반의 서버가 RPC 호출에 응답하면 명령을 완료할 수 있어야 한다. -
마지막으로 로그 일관성을 유지하기 위해
타이밍 의존성을 피해야 한다. 타임스탬프를 통해 최신 데이터를 판단 시 메시지 지연이나 고장난 클럭 문제가 발생하면 최신 데이터를 판단하기 어렵기 때문이다.
📌 문제상황
- 고장난 클럭 케이스 : 노드 A 의 시간이 고장나서 1시간 뒤로 설정되면, 과거의 데이터라고 판단하여 최신성을 보장받지 못할 수 있다.
- 네트워크 지연 케이스 : 노드 A 의 변경사항이 네트워크 지연으로 인해 나중에 다른 노드에 도착하면, 다른 노드에선 A 의 과거 타임스탬프를 가진 데이터를 무시하거나 충돌 처리에 문제가 발생할 수 있다.
Raft를 구성하는 요소
Raft 설계 목표 중 하나는 기존에 이해하기 어려운 Paxos 를 대체할, 쉽게 이해할 수 있는 합의 알고리즘을 만드는 것이다.
Problem Decomposition: Raft 는합의라는 복잡한 문제를 해결하기 위해 보다 작은 문제로 쪼개서 해결하는 분할/정복 방법을 이용한다. Raft 는 크게 3개의 독립적인 문제(1. 리더 선출 2. 로그 복제 3. 안정성 보장)를 해결하며 하나의 합의 알고리즘을 구성한다.
- 리더 선출 : 기존 리더 노드에 장애가 발생하거나 실패할 때 새로운 리더를 선출한다.
- 로그 복제 : 오직 리더만 클라이언트가 요청하는 로그 생성을 허용하여 전체 클러스터에 걸쳐 로그를 복제할 수 있다.
- 안정성 : Raft 의 핵심적인 안정성은 상태 머신으로, 만약 어떤 서버가 특정 로그 항목을 자신의 상태 머신에 적용(commit)했다면 다른 서버는 동일한 로그 인덱스에 다른 명령(command)을 적용할 수 없다.
Simplify the State Space (상태 공간 단순화): 시스템이 가질 수 있는 가능한 상태의 수를 줄여 시스템을 더 일관성 있게 만들고 비결정성을 제거한다. 이는 합의 알고리즘의 복잡성을 줄이기 위해 고안된 개념으로, 분산 시스템에서 발생할 수 있는 노드의 다양한 상태 변화(전이)를 단순화하여 알고리즘의 이해와 구현을 쉽게 만든다.
Raft 의 상태 공간 단순화는 2가지 원칙을 따른다.
첫 번째는 상태를 단순화하는 것으로, 노드의 상태를 리더 / 팔로워 / 후보자 세 가지로 제한한다.
각 노드는 임기(term)마다 세 가지 상태 중 하나로만 존재하며, 각 역할에 따른 동작을 제한하여 이해하기 쉬운 합의 알고리즘을 설계한다.
노드는 내부적으로 임기(term) 를 가지고 있어 각 임기마다 하나의 리더를 선출하여 해당 임기의 대표성을 가진다.
임기는 매 임기마다 1씩 증가하는(auto-increment) 형태로 구분되며, 각 노드마다 임기 전환은 다른 시간대에 포착될 수 있다.
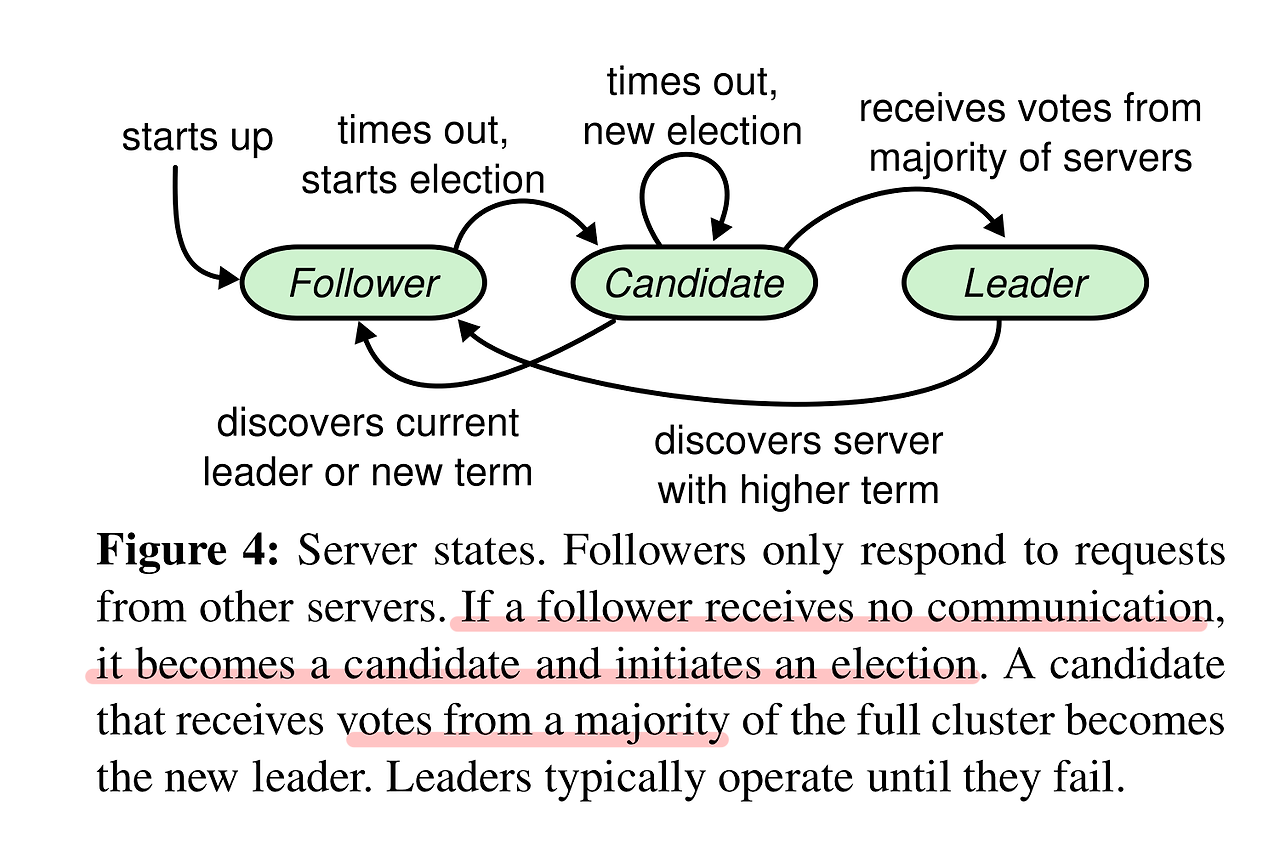
- 리더 Leader : 클러스터는 하나의 리더와 나머지 팔로워로 구성된다. 오직 리더만이 클라이언트의 모든 요청을 수신하며 자신의 로컬에 로그를 적재한 후 팔로워에게 요청을 전달한다.
- 팔로워 Follower : 팔로워는 클라이언트로부터 받은 요청을 리더에게 리다이렉트 하거나, 리더에게 전달받은 요청만 수신하여 처리하는 역할을 수행한다.
- 후보자 Candidate : 새로운 리더를 선출하기 위해 후보가 된 상태이다. 리더 선출과정에서 여러 후보가 생길 수 있다.
두 번째는 과정을 단순화하는 것으로, 리더 선출과 로그 복제 과정을 단계별로 분리하여 혼동을 줄이고 상태 전이를 명확히 구분한다. 리더 선출(선거)는 클러스터의 리더 노드를 선택하는 과정이고
로그 복제는 리더가 선택된 후 클라이언트의 명령을 일관되게 복제하는 과정이다. 이처럼 두 가지 절차를 분리함으로 각 단계에서 필요한 상태와 동작이 독립적으로 정의돼 복잡성을 줄일 수 있다.
각 노드는 RPC(원격 프로시저 호출)로 서로 통신하며, 합의 알고리즘에는 2종류의 RPC (RequestVote RPC 와 AppendEntries RPC) 를 필요로 한다.
RequestVote RPC 는 리더 선출 기간 중 후보자가 호출하는 RPC로 다른 팔로워 노드들에게 자신에게 투표하라는 메시지를 담아 보낸다.
AppendEntries RPC 는 리더들이 로그를 다른 노드에 복제하거나, 하트비트 통신을 위해 사용된다.
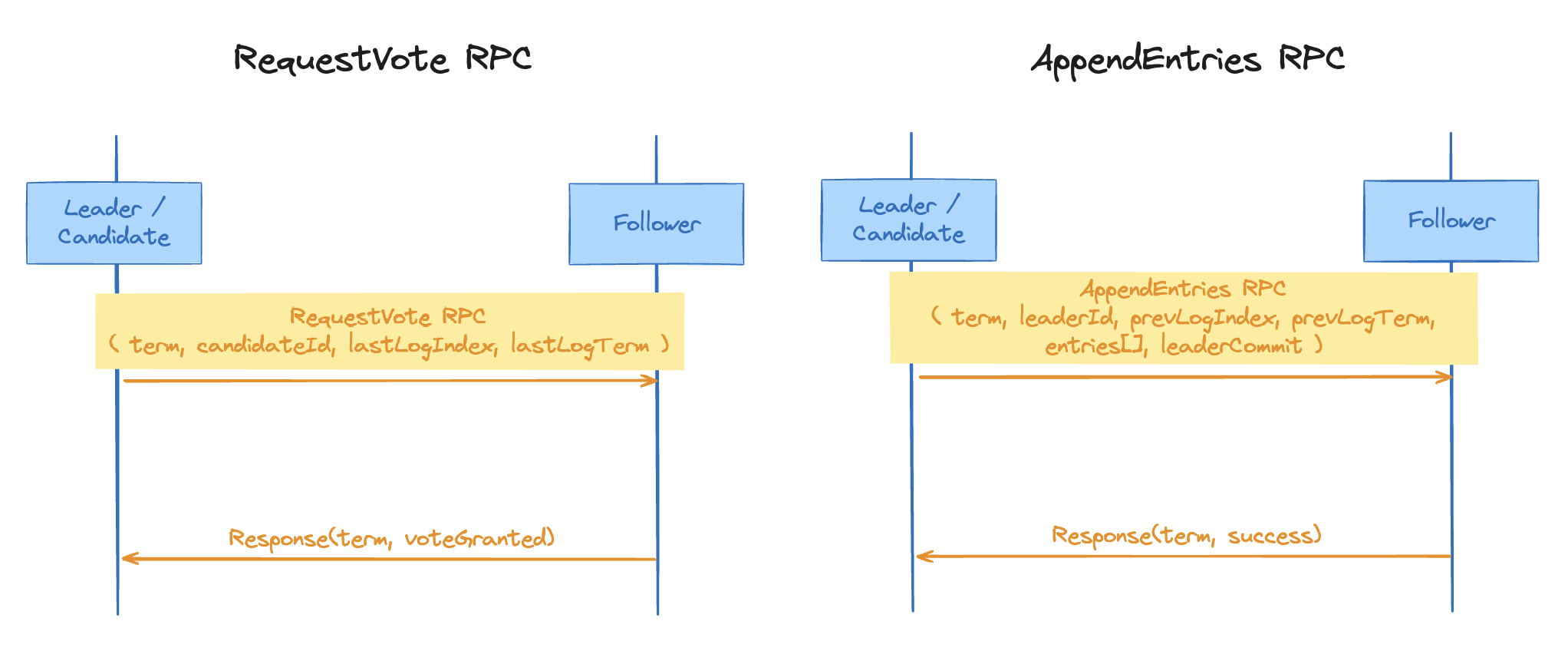
리더가 전송하는 AppendEntries RPC 는 아래 요소들로 이뤄져있다.
- term : 현재 leader의 임기
- leaderId : leader id
- prevLogIndex : 바로 이전의 log index
- prevLogTerm : 바로 이전의 log index에 기록된 임기(term)
- entries[] : 저장할 로그 엔트리 (비어있으면 heartbeat용)
- leaderCommit : 현재 leader의 commitIndex
리더 선출
Raft 는 리더 선출을 위해 Heartbeat 메커니즘을 사용하며, 리더는 주기적으로 하트비트를 팔로워 노드로 전송하여 각 노드간 상태를 확인한다.
(하트비트는 로그항목을 포함하지 않은 AppendEntries RPC 로 보낸다.)
클러스터의 노드는 최초 부팅 시 팔로워 상태로 시작한다. 이 때 각 노드마다 랜덤한 타임아웃(election timeout)이 설정돼 있는데, 이 타임아웃 내에 하트비트를 수신하지 못하면 리더가 정상 상태가 아니라 판단하여 새로운 리더를 선출하기 위한 선거를 시작한다.
1️⃣ 타임아웃을 먼저 초과한 노드(팔로워)는 선거를 시작하기 위해 자신의 현재 임기 상태를 증가 시키고 후보자(Candidate) 상태로 전환한다.
2️⃣ 해당 후보자는 스스로에게 투표 후, 클러스터 내 노드들에 병렬적으로 RequestVote RPC를 전송해 자신을 리더로 투표해달라는 사인을 보낸다.
3️⃣ 선거에서 승리하면 (정족수 이상 투표) 해당 후보자는 리더로 전환된다.
아래의 케이스 처럼 후보자가 둘 이상 등장하면 리더 선출에 실패하는 경우도 존재한다.
- a) 다른 후보자가 먼저 과반수 투표를 받아 리더가 되는 경우나,
- b) 선거에서 아무도 승리하지 못한 채 특정 시간이 지난 경우엔 다시 팔로워 상태로 전환된다.
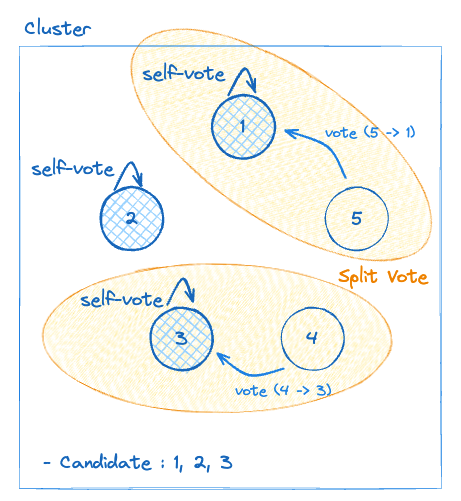
예를 들어, 5개 노드의 클러스터는 과반수(정족수) 3 이상의 투표를 받아야 리더로 선출될 수 있다. 이 때 3개의 후보자가 동시에 나타나면 분할 투표 현상으로 인해 누구도 과반을 얻지 못한 경우엔 해당 임기는 그대로 종료되고 새로운 임기(term + 1)에서 재선거가 시작된다. Raft 에서는 이전 선거처럼 분할 투표 문제가 발생하는 걸 방지하기 위해 선거가 시작될 때 마다 후보자 노드들의 Election Timeout 값을 랜덤하게 재조정한다.
그러나 만약 클러스터 안에 죽은 노드가 너무 많아서 어떤 노드도 과반의 득표를 얻을 수 없는 상황이라면 리더 선출이 불가능해진다. 클러스터로 들어오는 명령이 오직 리더로부터 팔로워에게 일방향으로 전파되는 알고리즘의 특성상, 리더의 부재는 클러스터 관리 기능 전체를 멈추게 만든다.
모든 서버들은 동일 임기 내에 선착순으로 오직 하나의 노드에게 투표한다(1 노드 1 투표). 그리고 정족수 이상 득표한 후보자만이 리더로 선출되는 규칙은 적어도 하나의 후보자만 특정 임기 내에서 승리할 수 있음을 보장한다.
랜덤 타임아웃
Raft 에선 여러 후보자가 발생한 후 투표가 동률로 끝나는 상황을 Split Vote 라 한다. 이 경우 투표는 결렬되고 재투표를 진행해야한다. 이런 케이스 발생을 줄이기 위해 각 서버는 랜덤으로 타임아웃 시간이 설정된다. 특정 후보자가 과반수 표를 얻지 못해 선거가 실패하면, 일정 시간 후 다시 (랜덤한) 타임아웃이 발생하고 새로운 선거가 시작된다. 랜덤 타임아웃 덕분에 선거가 여러 번 반복될수록 동시에 후보가 출마할 확률이 줄어, 결국 한 후보자가 과반수 표를 얻어 리더로 선출될 가능성이 높아진다.
javaprivate long pollFollowerAsVoter(FollowerState state, long currentTimeMs) { GracefulShutdown shutdown = this.shutdown.get(); final long backoffMs; if (shutdown != null) { ... } else if (state.hasFetchTimeoutExpired(currentTimeMs)) { logger.info("Become candidate due to fetch timeout"); transitionToCandidate(currentTimeMs); backoffMs = 0; } else if (state.hasUpdateVoterPeriodExpired(currentTimeMs)) { ... } else { ... } ... } public boolean hasFetchTimeoutExpired(long currentTimeMs) { fetchTimer.update(currentTimeMs); return fetchTimer.isExpired(); } public boolean isExpired() { return currentTimeMs >= deadlineMs; }
로그 복제
Raft 의 로그는 index(위치 값), 임기 번호, 상태 변경 명령(command) 3가지로 구성된 엔트리의 집합체를 의미한다.
Raft 는 어떻게 로그 일관성을 유지하여 복제 상태 머신을 구성할까?
먼저 클라이언트가 새로운 요청을 리더에게 전송하면, 리더는 이 요청(command)을 자신의 로그에 추가(append)한다. 이후 리더는 AppendEntries RPC 를 모든 노드에 병렬적으로 요청해 해당 항목을 복제하도록 한다. 그 후 과반수 합의 과정을 거치는데, 리더는 클러스터 과반수(정족수)에서 로그가 복제된 것을 확인하면, 자산의 로그 엔트리를 커밋하고 팔로워에게도 변경 사항이 커밋됐음을 보낸다. 그 후 팔로워도 자신의 로그 엔트리를 커밋한다(그전까진 복제만 해둠)
-
먼저 클라이언트가 새로운 요청을 리더에게 전송하면, 리더는 이 요청(command)을 자신의 로그에 추가(append)한다.
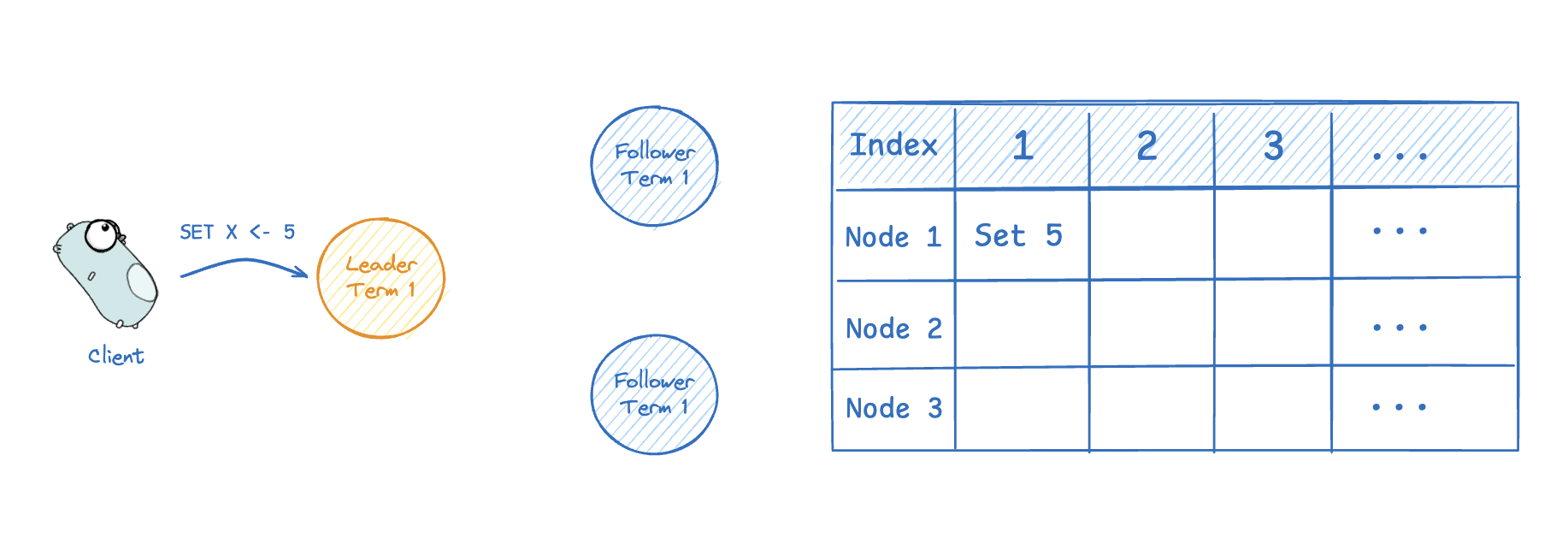
-
이후 리더는 AppendEntries RPC 를 모든 노드에 병렬적으로 요청해 해당 항목을 복제한다.
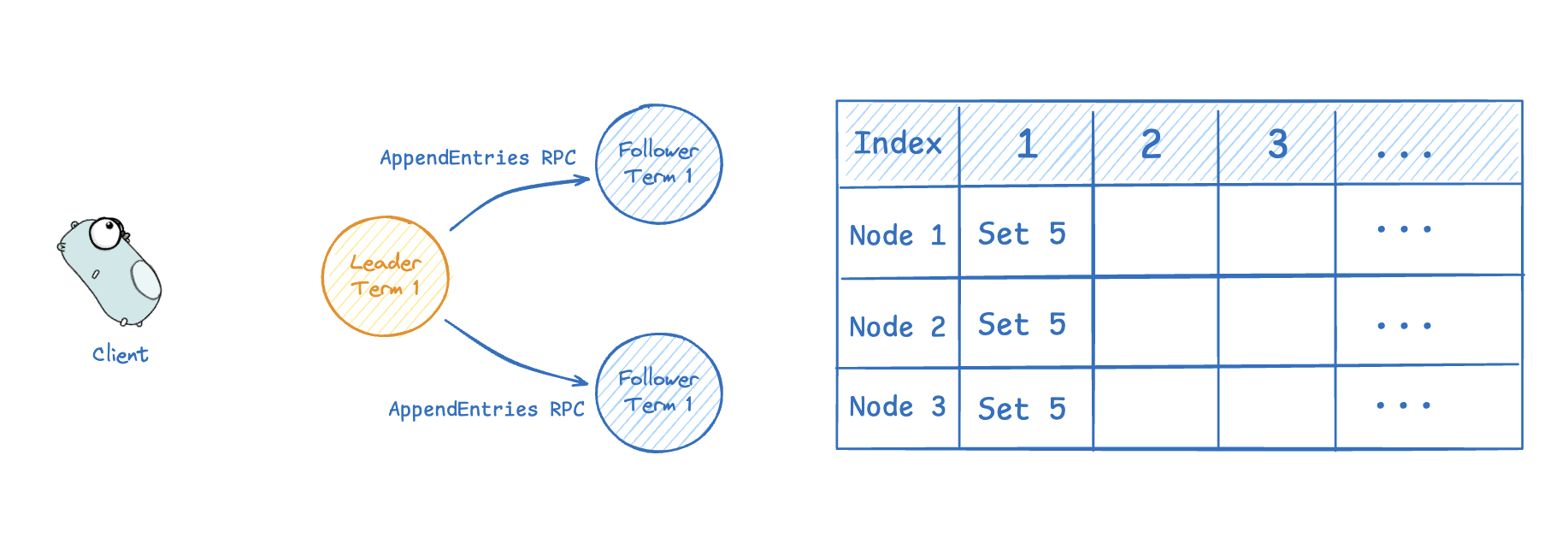
-
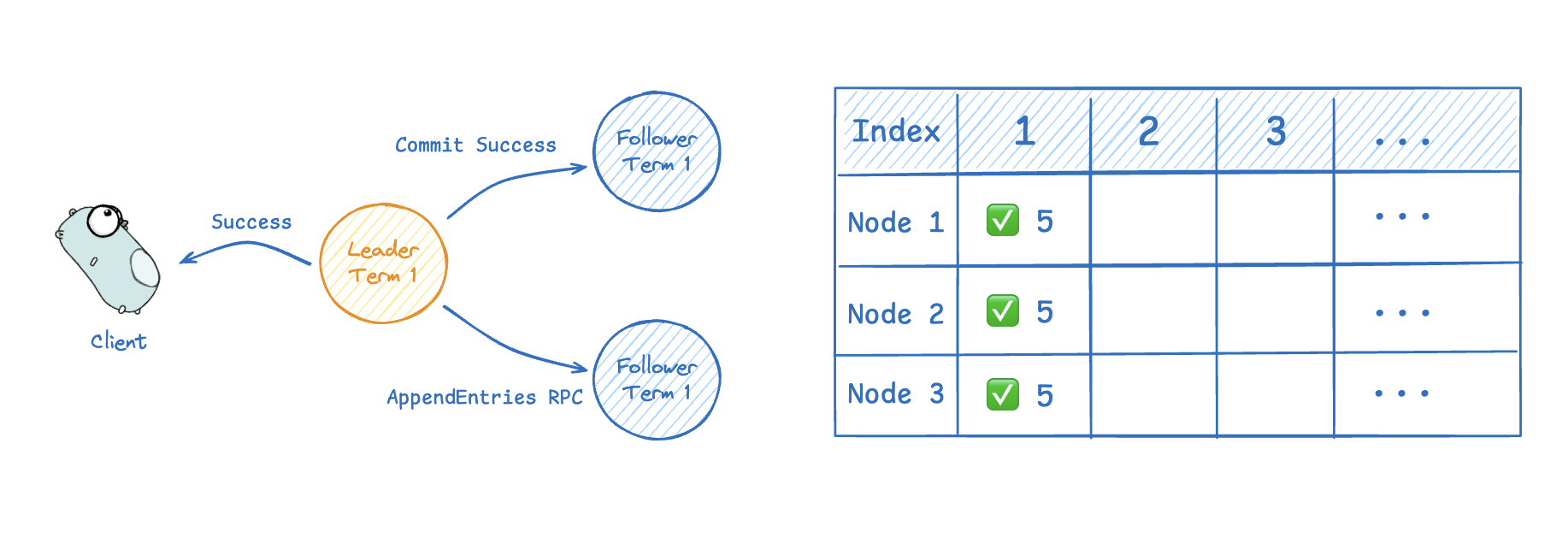
그 후 과반수 합의 과정을 거치는데, 리더는 클러스터 과반수(정족수)에서 로그가 복제된 것을 확인하면, 자산의 로그 엔트리를 커밋하고 팔로워에게도 변경 사항이 커밋됐음을 보낸다. 아래 이미지에서 정족수는 2 (= n/2 + 1)이므로 두 팔로워 중 하나만 복제 성공하더라도 해당 로그를 커밋할 수 있다.(초록 체크박스가 커밋을 의미한다.)
AppendEntries RPC 의 상세 동작 순서를 살펴보면,
- 리더로 부터 전달받은 term 이 Follower 현재 임기(currentTerm) 보다 낮으면 (term < currentTerm) return false
- 전달받은 prevLogIndex 에 해당하는 엔트리가 없으면 return false
- ex) 리더의 index 는 100 인데 복사하려는 follower 의 index 가 98인, prevLogIndex(=99)에 해당하는 entry 가 없는 경우
- 이미 존재하는 엔트리가 새로운 엔트리와 충돌이 발생한 경우(= 같은 index 지만 다른 term 일 경우)
- 기존 엔트리 삭제 후 새로운 엔트리 추가
로그 충돌 케이스
아래는 리더 노드 장애로 인해 노드 간 로그 항목이 다른 경우, 어떻게 일관된 로그 상태를 가질 수 있는지 과정을 설명한다.
-
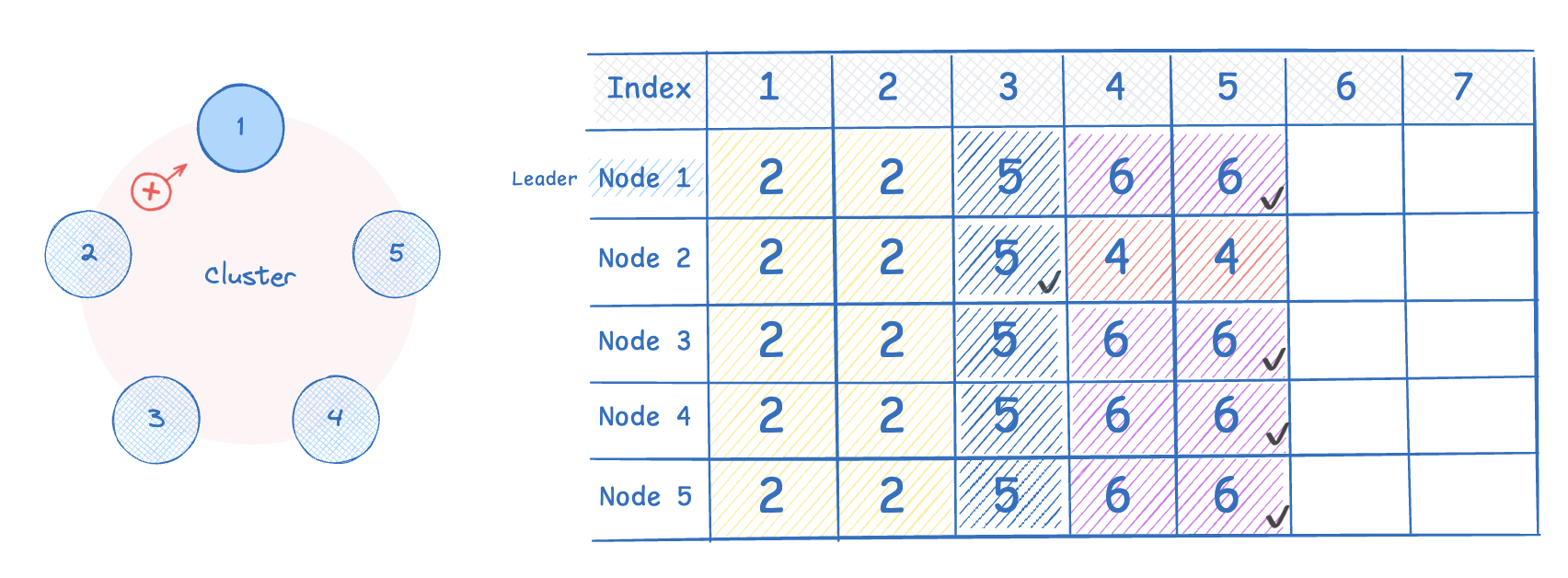
Node 2 는 클러스터의 다른 노드와 로그 상태가 불일치한 상태다. 리더의 현재 임기는 6 이므로 Node 2 는 임기 상태도 동기화 해야한다. 현재 클러스터 모든 Node 의 nextIndex 값은 6 이라 가정한다.
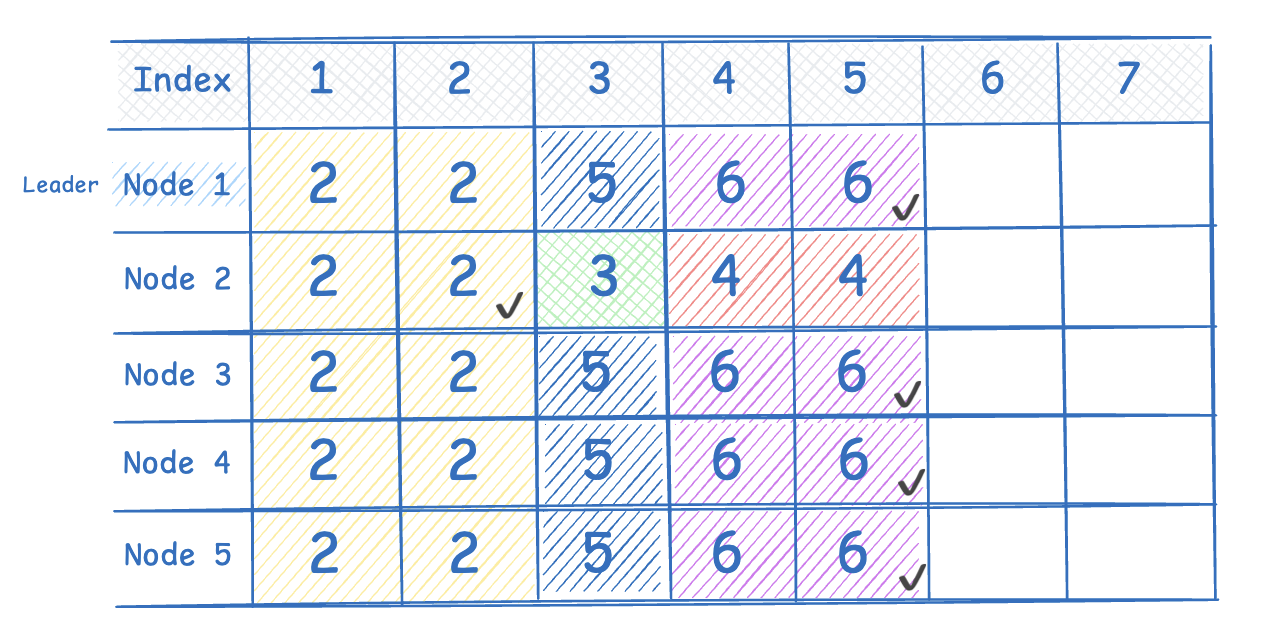
-
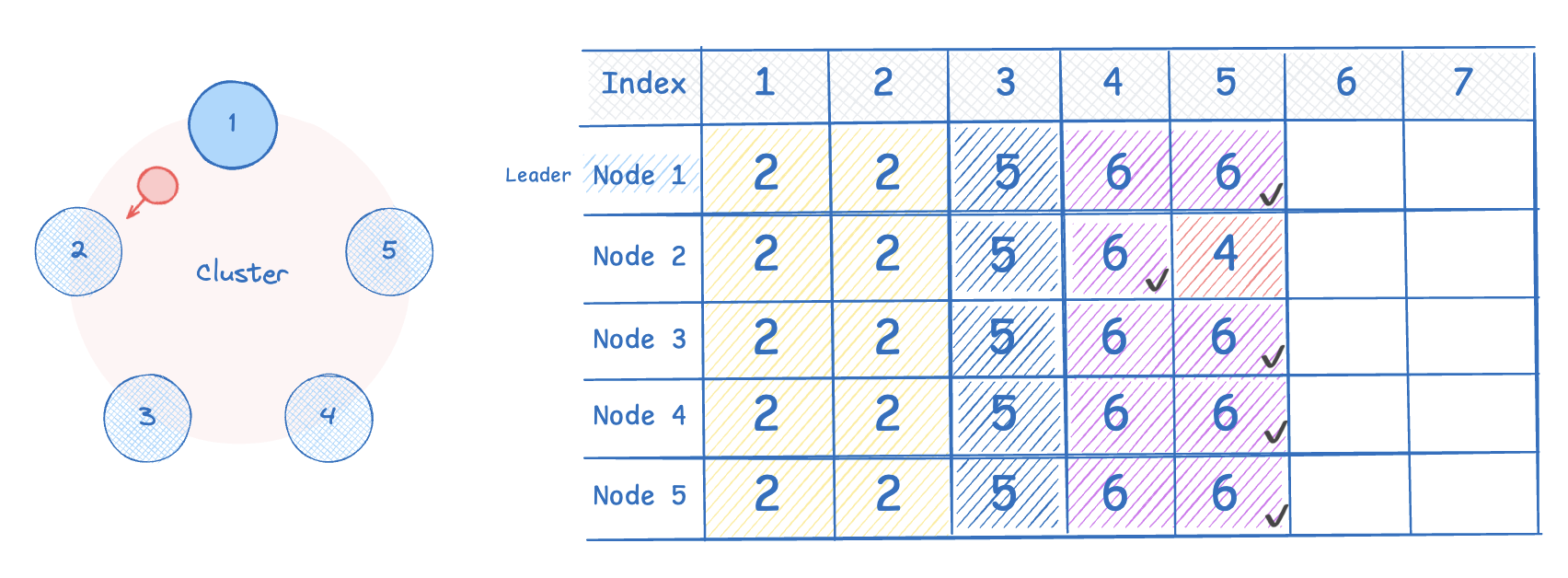
리더 노드의 heartbeat 를 수신한 node 2 는 match index=0 (일치 사항 없음) 이라 응답한다. 그럼 리더는 N2 의 nextIndex 를 5로 업데이트하고(6에서 하나 줄인 것), 리더 인덱스(5)의 엔트리 값을 N2 에 전달해 일치하는 것이 존재하는지 확인한다.(AppendEntries RPC)
-
여전히 일치하는 것이 없어 N2 는 실패 메시지를 응답한다.
-
실패 응답을 받은 리더는 nextIndex 를 4로 업데이트하고 다시 AppendEntries RPC 를 요청한다. 여전히 일치하는 것이 없으므로 동일 과정을 한번 더 반복하여 nextIndex 를 3으로 업데이트한다.
-
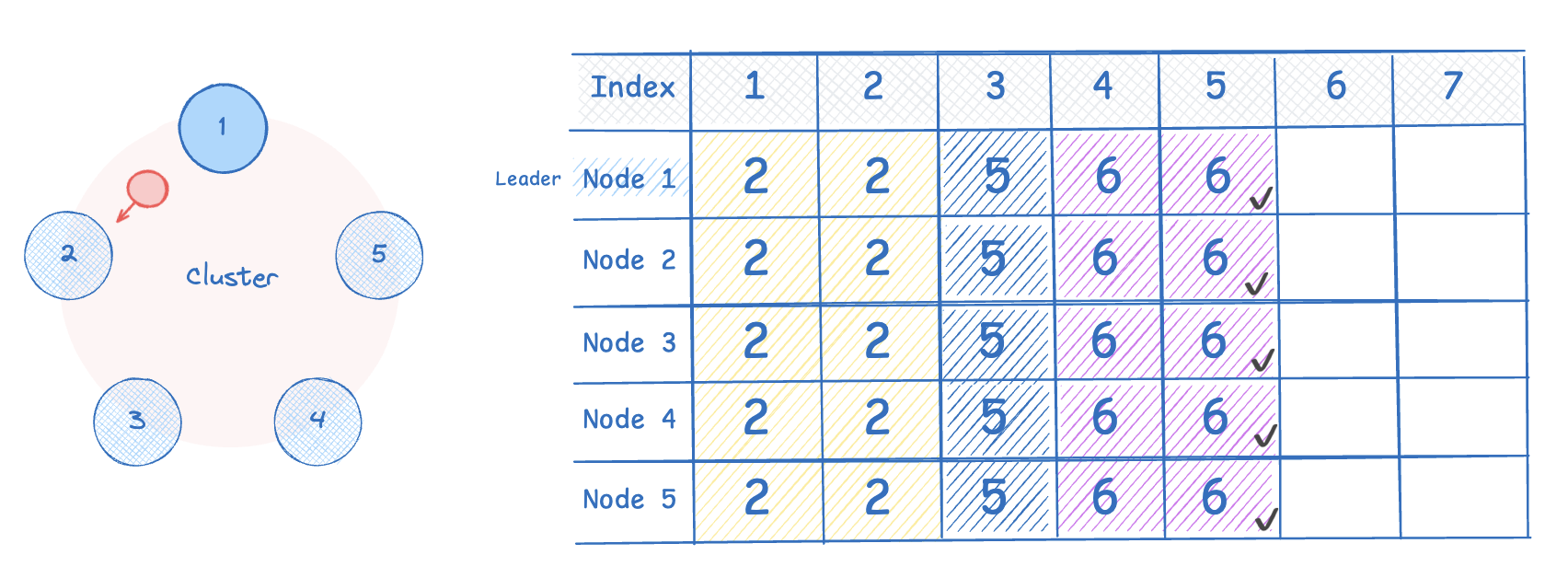
현재 N2 는 3번 인덱스의 로그를 커밋 하지 못했던 상황으로, 3번 인덱스를 커밋하고 로그가 일치한다고 리더에게 응답한다.
-
리더는 4번 인덱스의 값을 N2 에 전달하고, N2 는 이를 커밋한다.
-
5번 인덱스까지 커밋하여 최종적으로 모든 노드의 로그가 일관된 상태를 달성한다.
마무리
논문을 기반으로 Raft 합의 알고리즘의 전반적인 내용을 살펴봤다. Paxos 에 비해 이해하기 쉬운(?) 알고리즘을 설계하기 위해 상태 공간 단순화와, 문제 분할/정복 을 통한 합의 알고리즘의 전반적인 내용을 배울 수 있었다. 확실히 전반적인 내용은 잘 이해됐지만, 일부 노드에 장애가 발생하거나 로그 충돌, 선거 제한 같은 문제 상황을 극복하는 과정은 이해하기 까지 다소 시간이 걸렸다. 분산 시스템에서 로그 복제와 충돌 해소를 위해 어떤 방향으로 문제를 해결하는지 배울 수 있어 의미있는 논문 읽기였다.